
Bear-ly Audible Tracking Panda Vocalizations with STM32

Do you know what sound a panda makes? Over the last eight weeks, our team has been collaborating with the San Diego Zoo Wildlife Alliance to find ways to record, label, and store the various vocalizations produced by panda bears, polar bears, and several other species using specialized collars. While initially simple, the problem has posed several questions relevant to the field of computer hardware at large: how do you keep a low-power device running for periods of over a year? Can you collect only the relevant sounds, while avoiding environmental noise? What is the domain shift between a noisy MEMS microphone and high-quality training data?
This project is split into several engineering problems and a larger, overarching design problem: collecting microphone data, denoising that data, running lightweight inference, and storing the result are all fairly trivial issues on their own, but they become more complicated when the resources are heavily constrained and the target audience–intended to both collect and access the data–is unfamiliar with the technology. In particular, power consumption optimization and ease of use are dissimilar–and, in some cases, incompatible–goals. Thus, the goal of this project is not only to develop a bioacoustic device, but to solve an optimization problem.
This project was made possible thanks to the efforts of Milo Akerman, Francisco Irazaba, AnMei Dasbach-Prisk, and Hayden Dosseh, along with the teams who have worked on hardware and software previously.
Crossing the STM Barrier
The first issue our team faced was the system architecture. STM32 boards are, by design, more complex to work with than microcontrollers running on ESP32 or ESP8266. On one hand, peeling away layers of abstraction and letting you interact with the board at the register level (bare-metal programming) allows for lightning-fast operations and very low power overheads. On the other, it means you may be stuck for weeks debugging a linker file. The latter is a sacrifice more than acceptable for this project, but it did mean we would occasionally get stuck struggling against simple peripherals like USART or SPI.
It was once we got a firm grasp of the STM32H7 that we realized the boon that was its low-level design principles. At the end of the day, we were able to optimize our peripheral usage without needing to swap boards or mess with solder bridges–and it was then that we could really get to work.
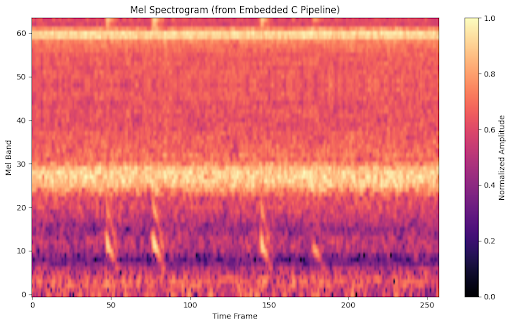
Output spectrogram from on-board MEMS microphone. Notice the noise at mel bands 20-30, 60
20 Milliamps or Less
If you want a board running continuously for a year on 6kg of batteries (just slightly less than 1% of the body weight of a female panda bear) you need, on average, a current draw of 20mA or less. Concerningly, previous studies placed the power estimates for a system like ours at about 100mA for inference alone on a TinyML model. Therefore, our first task was to build a system as power efficient as possible. This is how we arrived at our various prototypes for sleep systems, a task made easy by the STM32H7’s various inbuilt low-power modes and difficult by the lack of a good wake-up trigger. A convenient side effect of triggered wake-up is that, since the data is only collected when something of interest occurs, there is no need to sift through or store noise, thereby saving processing power, storage space, and much-needed time for the scientists. For weeks we combed papers and scribbled over our whiteboard, trying to determine what the best way to issue a wake-up signal was, before arriving at two possible solutions: we either implemented digital signal processing (DSP) on the board’s second, less power-hungry core (the Cortex-M4) or we designed and stress-tested an analog signal processing circuit.
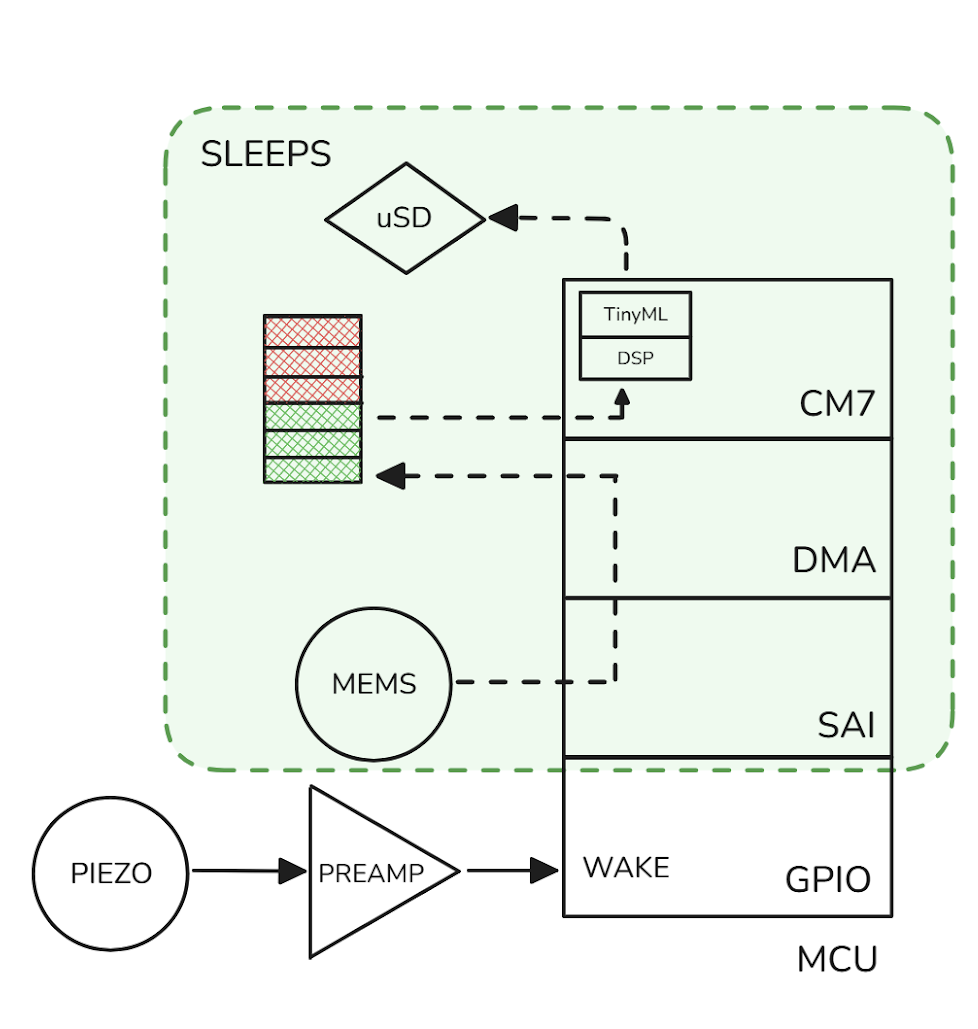
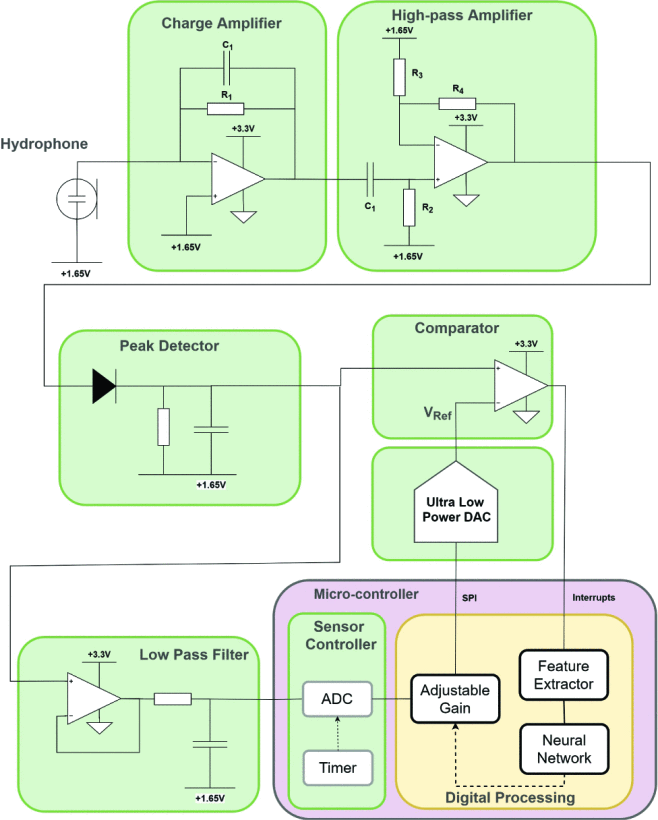
Left: System diagram of our collar, with simplified piezo wake-up circuit (analog signal processing) at bottom. Right: A similar, complete piezo wake-up circuit. Marzetti et al., 2020
Due to the complexity of the latter system, along with a lack of in-house prototyping material and a wealth of possible failure modes, we decided to go for the DSP approach. We settled on a system which performs very basic operations on the M4 core, storing the audio data in shared memory with its sister M7 core. This allows us to switch between the two quickly, only ever having one active at a time, while relaying the data seamlessly.
We conducted two power studies on our system. One early on, which showed high figures mostly due to unoptimized code and improper clock frequencies, a second one with full peripheral integration. By the end, our system was showing promise in terms of power consumption, allowing us to deploy for durations exceeding both the original estimates and the project specifications.
| First Study | Second Study | |
|---|---|---|
| Baseline - Wake | 13.43 mA | 6.99 mA |
| Baseline - Sleep | 2.9 mA | 2.7 mA |
| Mic + SAI + DMA | 23.6 mA | 10.37 mA |
| DSP + Inference | 16.0 mA | 12.46 mA |
| MicroSD Write | 14.1 mA | 7.74 mA |
Better-than-Algorithmic Compression
Finally, we arrive at another important issue: how do you store data securely, for a year or more, under restrictive and unpredictable conditions? There is a simple solution: SD cards are small, light, and mostly lossless, in addition to having fast and power-efficient write cycles. The biggest issue with this approach is that data can’t be collected until the deployment is complete, a feature that can prove very inconvenient, depending on the use case. Given that our collaborators have an already established LoRa (Long Range) network, we did a lot of work trying to make our system integrate wireless communications as an alternative to SD storage.
Famously, wireless communications are very power-hungry. LoRa uses less power by transmitting data through “chirps”, at the cost of significantly lower bandwidth and longer uplink times. More importantly, LoRa is still by far the most power-intensive of our system. To reduce this issue, and to avoid blocking the network for too long, it quickly became apparent that we would need to compress our audio files significantly. In fact, if we reduced it enough for a full transmission, we could avoid running inference on-device at all, and classify the sound files with more powerful compute resources elsewhere in the network. For now, we decided to see how far we could take the compression. And, after implementing SD writes with FATFS, we stumbled upon an interesting–and promising–alternative to audio codecs: autoencoders.
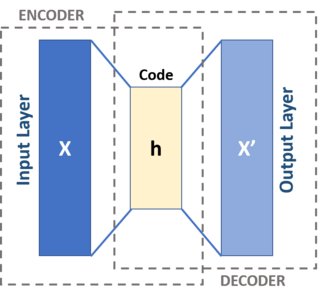
The idea behind autoencoders is as follows: a multi-layer perceptron (the encoder) is trained to compress, for example, an image of a spectrogram into a set of embeddings, which another MLP (the decoder) can then decompress into a reasonably accurate representation of the original image. If you sever the two parts of the model, you get a section which can encode images into a smaller representation (known as the “latent space”) and a section which can decode it to its original state. Why would you use this, instead of compressing your audio algorithmically (e.g., MP3)? In theory, an autoencoder could reduce the amount of information significantly more than an algorithm by ignoring aspects of the audio irrelevant to classification and only focusing on the features that distinguish two spectrograms you care about.

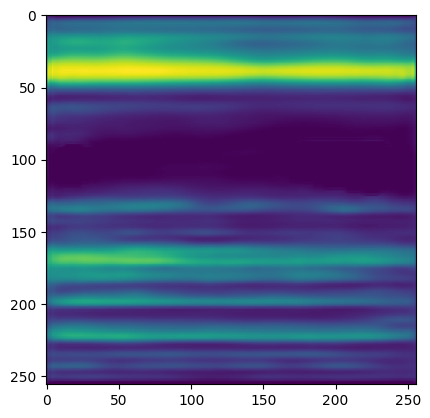
Sample autoencoder input and output, spectrograms courtesy of Anu Jajodia
Putting everything together, we arrive at a cutting-edge device capable of acting as a low-power edge node within and without an external network: a versatile device for analyzing animal behavioral data, which ultimately has the potential to aid countless conservation efforts. We hope our work will be of use to the San Diego Zoo, and continue to be iterated on for years to come.